
一、目录
- kafka详解
- 用户登录方案
二、实验结果和学习内容
Kafka 详解
Kafka是一种分布式的,基于发布/订阅的消息系统。主要设计目标如下:
- 以时间复杂度为O(1)的方式提供消息持久化能力,即使对TB级以上数据也能保证常数时间的访问性能
- 高吞吐率。即使在非常廉价的商用机器上也能做到单机支持每秒100K条消息的传输
- 支持Kafka Server间的消息分区,及分布式消费,同时保证每个partition内的消息顺序传输
- 同时支持离线数据处理和实时数据处理
而我们的项目目标是完成一款Feed流App,显然消息队列系统是非常重要的。
- 送达保证
消息队列提供的冗余机制保证了消息能被实际的处理,只要一个进程读取了该队列即可。在此基础上,部分消息系统提供了一个”只送达一次”保证。无论有多少进程在从队列中领取数据,每一个消息只能被处理一次。这之所以成为可能,是因为获取一个消息只是”预定”了这个消息,暂时把它移出了队列。除非客户端明确的表示已经处理完了这个消息,否则这个消息会被放回队列中去,在一段可配置的时间之后可再次被处理。 - 顺序保证
在大多使用场景下,数据处理的顺序都很重要。消息队列本来就是排序的,并且能保证数据会按照特定的顺序来处理。部分消息系统保证消息通过FIFO(先进先出)的顺序来处理,因此消息在队列中的位置就是从队列中检索他们的位置。 - 缓冲
在任何重要的系统中,都会有需要不同的处理时间的元素。例如,加载一张图片比应用过滤器花费更少的时间。消息队列通过一个缓冲层来帮助任务最高效率的执行–写入队列的处理会尽可能的快速,而不受从队列读的预备处理的约束。该缓冲有助于控制和优化数据流经过系统的速度。
结构
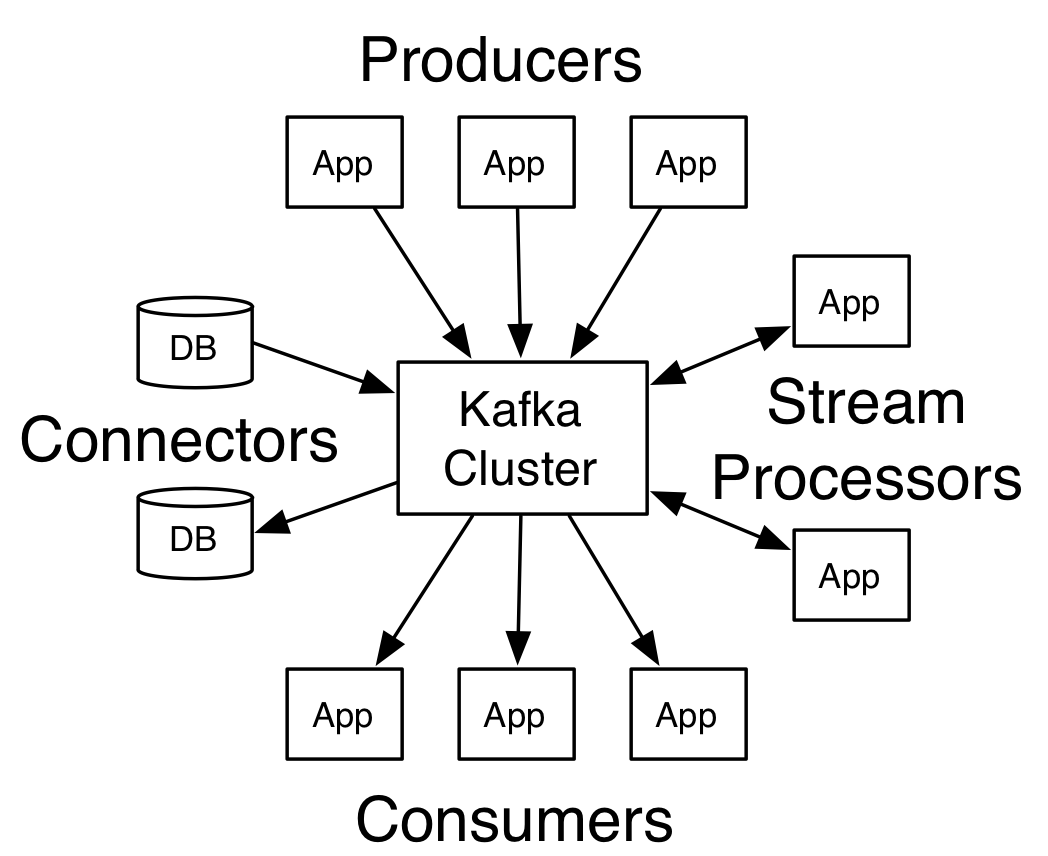
- Broker
Kafka集群包含一个或多个服务器,这种服务器被称为broker - Topic
每条发布到Kafka集群的消息都有一个类别,这个类别被称为topic。(物理上不同topic的消息分开存储,逻辑上一个topic的消息虽然保存于一个或多个broker上但用户只需指定消息的topic即可生产或消费数据而不必关心数据存于何处)
- Partition
parition是物理上的概念,每个topic包含一个或多个partition,创建topic时可指定parition数量。每个partition对应于一个文件夹,该文件夹下存储该partition的数据和索引文件
- Producer
负责发布消息到Kafka broker
- Consumer
消费消息。每个consumer属于一个特定的consumer group(可为每个consumer指定group name,若不指定group name则属于默认的group)。使用consumer high level API时,同一topic的一条消息只能被同一个consumer group内的一个consumer消费,但多个consumer group可同时消费这一消息。
kafka的四个核心Api
- 应用程序使用producer API发布消息到1个或多个topic中。
- 应用程序使用consumer API来订阅一个或多个topic,并处理产生的消息。
- 应用程序使用streams API充当一个流处理器,从1个或多个topic消费输入流,并产生一个输出流到1个或多个topic,有效地将输入流转换到输出流。
- connector API允许构建或运行可重复使用的生产者或消费者,将topic链接到现有的应用程序或数据系统。
kafka配置说明
Producer
Properties props = new Properties();
props.put("bootstrap.servers", "master:9092,slave1:9092,slave2:9092");
props.put("acks", "all");
props.put("retries", 0);
props.put("batch.size", 16384);
props.put("key.serializer", StringSerializer.class.getName());
props.put("value.serializer", StringSerializer.class.getName());
KafkaProducer<String, String> producer = new KafkaProducer<String, String>(props);其中:
- bootstrap.servers: kafka的地址。
acks:消息的确认机制,默认值是0;
- acks=0:如果设置为0,生产者不会等待kafka的响应。
- acks=1:这个配置意味着kafka会把这条消息写到本地日志文件中,但是不会等待集群中其他机器的成功响应。
- acks=all:这个配置意味着leader会等待所有的follower同步完成。这个确保消息不会丢失,除非kafka集群中所有机器挂掉。这是最强的可用性保证。
- retries:配置为大于0的值的话,客户端会在消息发送失败时重新发送。
- batch.size:当多条消息需要发送到同一个分区时,生产者会尝试合并网络请求。这会提高client和生产者的效率。
- key.serializer: 键序列化,默认org.apache.kafka.common.serialization.StringDeserializer。
- value.deserializer:值序列化,默认org.apache.kafka.common.serialization.StringDeserializer。
配置好之后,便可以生产数据了:
producer.send(new ProducerRecord<String, String>(topic,key,value));其中的参数:
- topic:消息队列的名称,可以先行在kafka服务中进行创建。如果kafka中并未创建该topic,那么便会自动创建!
- key:键值,也就是value对应的值,和Map类似。
- value:要发送的数据,数据格式为String类型的。
Consumer
Properties props = new Properties();
props.put("bootstrap.servers", "master:9092,slave1:9092,slave2:9092");
props.put("group.id", GROUPID);
props.put("enable.auto.commit", "true");
props.put("auto.commit.interval.ms", "1000");
props.put("session.timeout.ms", "30000");
props.put("max.poll.records", 1000);
props.put("auto.offset.reset", "earliest");
props.put("key.deserializer", StringDeserializer.class.getName());
props.put("value.deserializer", StringDeserializer.class.getName());
KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(props);其配置如下:
- group.id:组名 不同组名可以重复消费。例如你先使用了组名A消费了kafka的1000条数据,但是你还想再次进行消费这1000条数据,并且不想重新去产生,那么这里你只需要更改组名就可以重复消费了。
- enable.auto.commit:是否自动提交,默认为true。
- auto.commit.interval.ms: 从poll(拉)的回话处理时长。
- session.timeout.ms:超时时间。
- max.poll.records:一次最大拉取的条数。
auto.offset.reset:消费规则,默认earliest 。
- earliest:当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,从头开始消费 。
- latest:当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,消费新产生的该分区下的数据 。
- none:topic各分区都存在已提交的offset时,从offset后开始消费;只要有一个分区不存在已提交的offset,则抛出异常。
首先需要需要先订阅一个topic,也就是指定消费哪一个topic:
consumer.subscribe(Arrays.asList(topic));订阅之后,即可从kafka中拉取数据:
ConsumerRecords<String, String> msgList=consumer.poll(1000);可以使用for(;;)循环来进行进行监听:
for (;;) {
msgList = consumer.poll(1000);
if (null != msgList && msgList.count() > 0) {
for (ConsumerRecord < String, String > record: msgList) {
//消费100条就打印 ,但打印的数据不一定是这个规律的
if (messageNo % 100 == 0) {
System.out.println(messageNo + "=======receive: key = " + record.key() + ", value = " + record.value() + " offset===" + record.offset());
}
//当消费了1000条就退出
if (messageNo % 1000 == 0) {
break;
}
messageNo++;
}
} else {
Thread.sleep(1000);
}
}用户登录方案
一个App首先除了内容就是个人账号了,而用户注册登录的方案是值得探讨的。而登录就需要使用到用户名和密码,为了安全起见,在登录过程中暴漏密码的次数越少越好。
首先,为了保证登录的安全性,最起码要使用Https协议
HTTPS(Secure Hypertext Transfer Protocol)安全超文本传输协议,是一个安全通信通道,基于HTTP开发,用于在客户计算机和服务器之间交换信息,实际上应用了安全套接字层(SSL)作为HTTP应用层的子层,简单来说它是HTTP的安全版。
但是,https协议需要到ca申请证书,一般免费证书很少,需要交费。
可以看到所有大型网站,例如京东,淘宝,支付宝,涉及到登录和支付的页面,url都是以https开头,这就意味着,这次通讯是使用https。开放平台的api,例如新浪微博,腾讯等,api请求都是以https开头的。https是业界常用的保证安全性的协议。
因此,涉及安全问题的api,都应该使用https协议。虽然,https为了保证安全性,在效率上是比http协议低。
基本的用户登录方案
在传统的web网站中,可以使用cookie+session来实现用户的登录维护
而在app后端,需要避免每次验证用户身份都需要传输用户名和密码,流程如下:
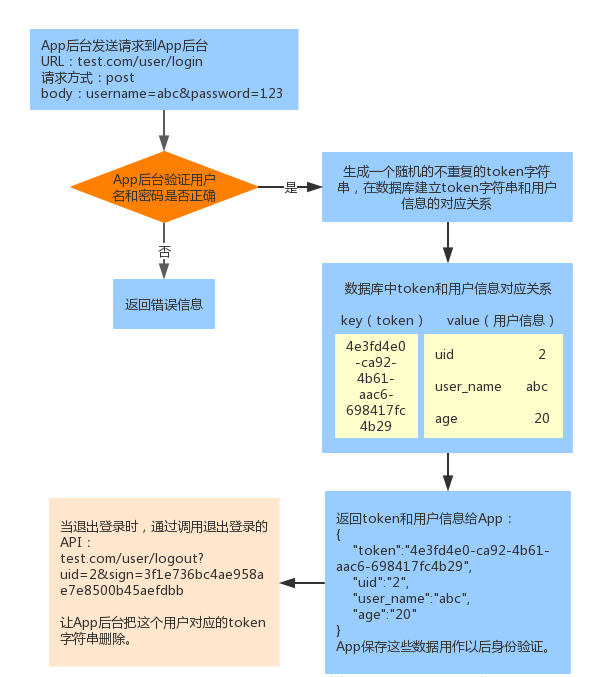
此时App已经获取到了token值,为了安全,不在网络上传输token,而使用签名校验(这里使用URL签名)的方式,API请求加上URL签名sign和用户id后如下:
test.com/user/update?uid=2&sign=3f1e736bc4ae958ae7e8500b45aefdbb&age=22这样,token就不需要附在URL上了。App后台签名校验流程如下:
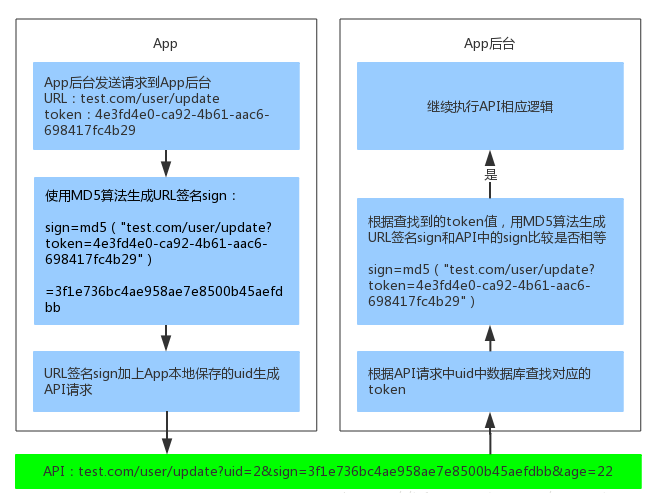
除此之外,还可以设置时间戳,这样在一定长度的时间之后,URL就失效了,也能提升安全性。
三、实验思考及感想
本周主要学习了常用的消息队列系统Kafka的架构和使用方法,当然,Kafka可能主要用在集群或者分布式系统中,并且在其中的效果也能体现的更好一些,而我们的项目由于设备限制和能力限制,可能最终只会是单服务器的后台。除此之外,也是项目开头的一个内容,即是App的用户登录方案,和我以前所学的Web开发中运用的方法不同,App中用到了token和sign来进行用户验证,对我来说是一个全新的方案,这是接下来要实现的内容,还有ssm框架的学习。